R&D
개발현황
테스트 코드 리팩토링에서 문서 자동화까지: 조현진 연구원
-
 관리자
관리자
- 2025.07.15
테스트 코드 리팩토링에서 문서 자동화까지
구조화와 반복 제거, 그리고 개발 효율화를 향한 여정
개요
개발이 진행될수록 코드의 규모와 복잡도는 자연스럽게 증가합니다.
이에 따라 테스트 코드와 문서 관리는 종종 뒤처지는 경우가 발생합니다.
이번 실험에서는 아래의 두 가지 주제를 중심으로 개선 작업을 수행하였습니다.
- 테스트 코드 리팩토링 – 반복을 제거하고, 구조를 정리하여 효율적인 테스트 체계를 마련하였습니다.
- README.md 자동화 실험 – Cursor, Claude, Task Master를 활용하여 문서 작성의 효율성을 높였습니다.
이 두 가지의 핵심은 다음과 같습니다.
“반복되는 작업을 구조화하고, 더 나아가 자동화하자.”
Part 1 – 테스트 코드 리팩토링 실험
리팩토링 배경
- 기능이 늘어날수록 테스트 케이스도 함께 증가합니다.
- 그러나 중복 코드와 일관되지 않는 코드 구조로 인해 유지보수에 어려움이 있었습니다.
핵심 개선 방향
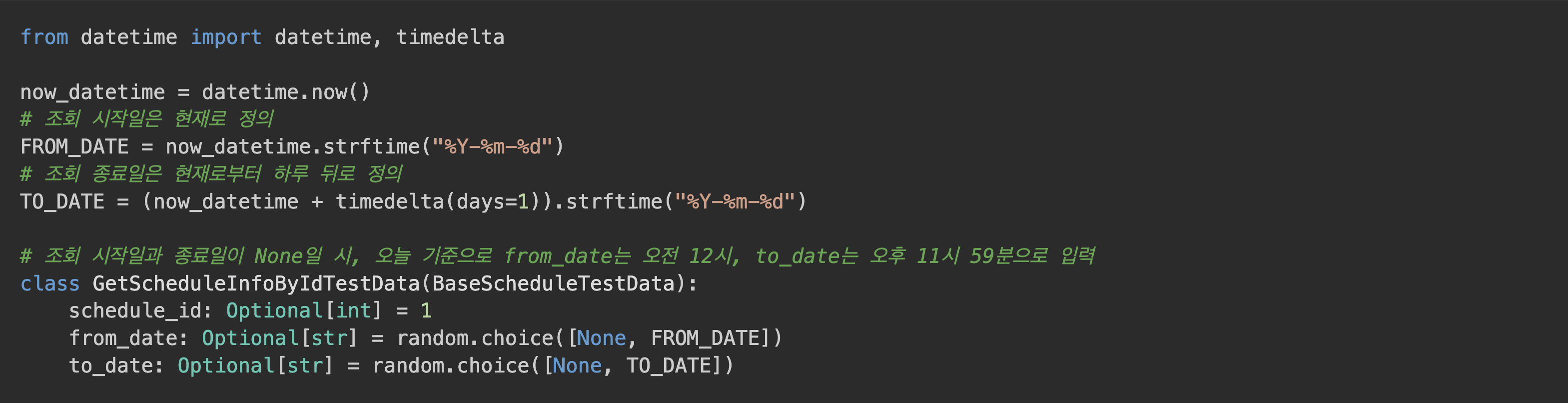
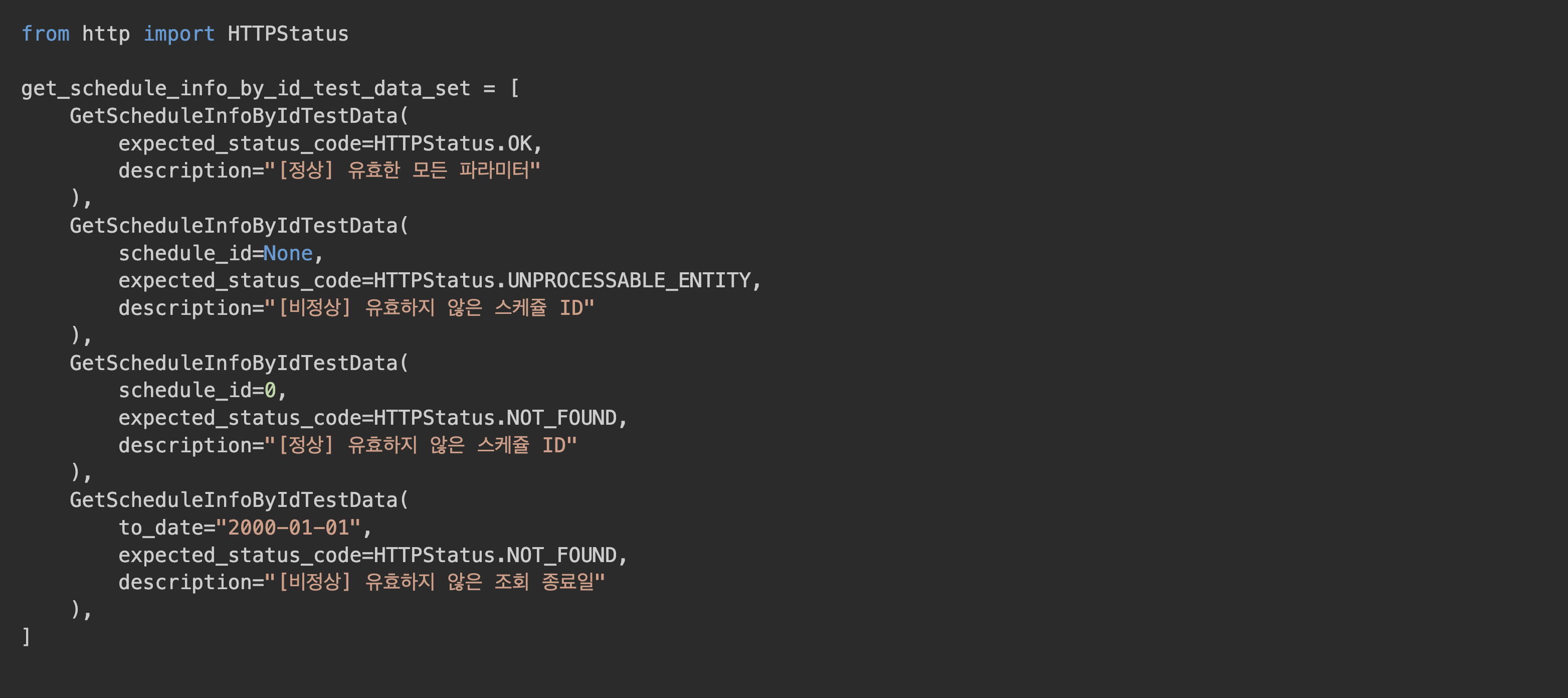
BaseTestData패턴 도입 – 공통 필드 정리@pytest.mark.parametrize활용 – 반복 제거description필드 도입 – 테스트 목적 명시
예시 구조

모든 테스트 코드에서 공통으로 쓰는 파라미터는 위와 같이 구조화하였습니다.
[Reference] Pydantic BaseModel: 데이터 유효성 검사 및 설정 관리를 위한 핵심 도구
Pydantic은 Python의 타입 힌트를 사용하여 데이터 유효성 검사와 설정을 관리하는 데 강력한 라이브러리입니다. 특히, BaseModel은 Pydantic의 핵심으로, 데이터 클래스처럼 동작하면서 런타임에 데이터 유효성 검사를 수행하는 데 최적화되어 있습니다. 이는 API의 요청/응답 데이터, 설정 파일, 또는 애플리케이션 내부에서 사용하는 데이터 구조를 정의할 때 매우 유용합니다.
Pydantic BaseModel의 기술적 특징 및 이점
타입 힌트 기반의 자동 유효성 검사:
- Python의 표준 타입 힌트(
int,str,List[str],Optional[int], 사용자 정의 클래스 등)를 사용하여 데이터 모델을 정의합니다. BaseModel은인스턴스 생성 시 자동으로 이 타입 힌트를 기반으로 데이터의 유효성을 검사합니다. 예를 들어,int로 선언된 필드에 문자열이 할당되면 오류를 발생시킵니다.- 이는 런타임에 데이터 스키마를 강제하여, 잘못된 데이터 형식을 미연에 방지하고 버그를 줄이는 데 크게 기여합니다.
- Python의 표준 타입 힌트(
데이터 파싱 및 직렬화/역직렬화:
- 다양한 입력 형식(Python
dict, JSON 문자열 등)을BaseModel인스턴스로 파싱하는 기능을 내장하고 있습니다. - 반대로,
BaseModel인스턴스를 Python 딕셔너리(dict())나 JSON 문자열(json())로 쉽게 직렬화할 수 있습니다. 이는 웹 API (FastAPI와 같은)에서 요청 본문을 자동으로 파싱하고 응답을 JSON으로 변환하는 데 핵심적인 역할을 합니다.
- 다양한 입력 형식(Python
데이터 불변성(Immutable Data):
BaseModel은 기본적으로 가변(mutable) 객체이지만, Config 클래스 내에 allow_mutation = False 또는 frozen = True 설정을 통해 불변(immutable) 객체로 만들 수 있습니다.- 불변 객체는 생성 후에는 내부 상태를 변경할 수 없으므로, 데이터의 일관성을 유지하고 의도치 않은 변경으로부터 보호하는 데 유용합니다. 특히 멀티스레딩 환경이나 함수형 프로그래밍 스타일에서 이점을 가집니다.
확장성과 재사용성 (상속):
- BaseModel은 일반적인 Python 클래스처럼 상속을 지원합니다. 이를 통해 공통 필드를 정의한 기본 모델(BaseTestData)을 만들고, 이를 상속받아 특정 시나리오에 필요한 추가 필드를 정의할 수 있습니다.
- 이는 코드 중복을 줄이고, 일관된 데이터 구조를 유지하며, 모델 변경 시 유지보수 용이성을 크게 향상시킵니다.
자동 문서화 (OpenAPI/JSON Schema):
- Pydantic 모델은 정의된 스키마를 기반으로 JSON Schema를 자동으로 생성할 수 있습니다.
- FastAPI와 같은 프레임워크는 이 JSON Schema를 활용하여 OpenAPI(Swagger UI) 문서를 자동으로 생성합니다. 이는 API 명세를 수동으로 작성할 필요 없이 항상 최신 상태를 유지할 수 있게 해주는 강력한 기능입니다.

[Reference] @pytest.mark.parametrize: 효율적인 테스트 데이터 주입과 반복 제거
@pytest.mark.parametrize는pytest프레임워크에서 제공하는 강력한 마커 중 하나로, 동일한 테스트 로직을 여러 가지 다른 입력 값으로 반복해서 실행할 때 사용됩니다. 이는 테스트 코드의 중복을 극적으로 줄이고, 가독성을 높이며, 새로운 테스트 케이스를 쉽게 추가할 수 있도록 돕습니다.
@pytest.mark.parametrize의 기술적 특징 및 이점
테스트 함수의 동적 확장:
@pytest.mark.parametrize("인자명", [데이터1, 데이터2, ...])형태로 사용됩니다.pytest는 이 데코레이터를 만나면, 지정된 인자명에 목록의 각 데이터를 순차적으로 주입하여 테스트 함수를 여러 번 실행합니다.- 각 실행은
pytest리포트에서 별도의 테스트 케이스로 인식되어, 어떤 데이터 조합에서 테스트가 실패했는지 명확하게 파악할 수 있습니다. 이는 디버깅 효율을 크게 높입니다.
다중 인자 및 복합 데이터 구조 지원:
- 여러 개의 인자를 동시에 파라미터화할 수 있습니다. 예를 들어,
@pytest.mark.parametrize("a,b", [(1,2), (3,4)])와 같이 사용하여 두 개의 인자에 다른 쌍의 데이터를 주입할 수 있습니다. - 단순 값뿐만 아니라, 튜플, 딕셔너리, 그리고 앞서 설명한 Pydantic
BaseModel인스턴스와 같은 복합적인 데이터 구조도 파라미터로 전달할 수 있습니다. 이 점이 테스트 코드 리팩토링에서BaseTestData와 같은 모델을 활용할 수 있게 하는 핵심입니다.
- 여러 개의 인자를 동시에 파라미터화할 수 있습니다. 예를 들어,
테스트 가독성 및 유지보수성 향상:
- 반복되는
for루프나 여러 개의 유사한 테스트 함수를 작성할 필요 없이, 단일 함수 내에서 다양한 시나리오를 커버할 수 있습니다. - 테스트 데이터는 테스트 로직과 분리되어 명확하게 정의되므로, 데이터만 보고도 어떤 시나리오를 테스트하는지 쉽게 이해할 수 있습니다.
- 새로운 테스트 케이스가 필요한 경우, 단순히 데이터 목록에 새 항목을 추가하기만 하면 되므로 유지보수가 매우 용이합니다.
- 반복되는
선택적 테스트 실행 및 마킹:
pytest마커와 함께 사용하여 특정 파라미터 조합에 대해서만 테스트를 건너뛰거나(skip), 예상된 실패로 처리(xfail)하는 등 고급 제어가 가능합니다.- 예를 들어,
@pytest.mark.parametrize("data", my_test_data_set, ids=str)와 같이ids인자를 사용하여 각 테스트 케이스에 대한 고유한 이름을 부여할 수 있어 테스트 결과 보고서의 가독성을 더욱 높일 수 있습니다.
주요 효과
| 항목 | 개선 내용 |
|---|---|
| 가독성 | description 필드를 활용하여 케이스 명확화 및 반복문 제거 가능 |
| 재사용성 | BaseTestData를 기반으로 동일 구조의 테스트를 단일 함수로 커버 가능 |
| 확장성 | 다양한 테스트에 케이스 BaseTestData 패턴 응용 가능 |
| 디버깅 효율 | 테스트 실패 시, 어떤 케이스인지 description과 assert_helper(HTTP 응답의 상태코드, 응답 본문 등을 검증하기 위해 자체적으로 구현한 유틸리티 함수입니다.)를 통해 명확하게 파악 가능 |
| 코드 길이 감소 | @pytest.mark.parametrize를 통해 중복 코드를 줄여 효율적으로 테스트 코드의 길이 관리 가능 |
Part 2 – README.md 문서 편의성 향상 실험
문제 인식
- 리팩토링 및 기능 추가 이후에도
README.md문서를 갱신하지 않아 최신 상태를 유지하기 어려웠습니다. - 수작업 편집은 반복적이고 비효율적이었고,
- 만일 신규 팀원이 합류할 경우, 프로젝트 구조 이해에 시간이 소요되는 문제도 존재했습니다.
해결 시도
| 도구 | 역할 |
|---|---|
| Cursor | Claude를 포함한 AI 모델을 호출할 수 있는 AI 기반 코드 에디터 |
| Claude | 코드 주석 및 구조 분석 후 문서 초안을 생성해주는 AI 모델 |
| Task Master (MCP) | Claude를 포함한 AI 모델의 요청 흐름을 관리하는 워크플로우 도구 (예: 코드 분석 요청 → 초안 생성 → 검토 및 수정 워크플로우) |
사용 방식 및 시행착오
자연어 형태가 아닌 명령어를 입력할 경우 MCP가 인식하지 못하는 문제가 있었습니다.
- 자연어 입력과 에러의 관계
예: 잘못된 명령어 (비자연어)
 → "setting"이라는 추상적 단어 때문에 LLM이 정확한 의도를 파악하지 못하여 에러가 발생했습니다.
→ "setting"이라는 추상적 단어 때문에 LLM이 정확한 의도를 파악하지 못하여 에러가 발생했습니다.예: 옳은 명령어 (자연어)
 또는
또는 → 정확한 자연어 형태의 명령어 형태로 입력하자 정상적으로 실행되었습니다. 이러한 경험을 통해 AI 모델과의 상호작용에서는 ""명령어의 명확성""과 ""자연어 기반의 구체적인 프롬프트""가 얼마나 중요한지 깨달았습니다.
→ 정확한 자연어 형태의 명령어 형태로 입력하자 정상적으로 실행되었습니다. 이러한 경험을 통해 AI 모델과의 상호작용에서는 ""명령어의 명확성""과 ""자연어 기반의 구체적인 프롬프트""가 얼마나 중요한지 깨달았습니다.
- 일부 CLI 명령어는 명세에 존재했지만, 실제 실행 환경에서는 동작하지 않았습니다.
→ Docker 기반 환경 설정을 재구성하여 해결하였습니다.
실험 목적
- README 자체를 완전히 자동화한 것은 아니며,
반복적인 갱신 작업에서 AI 요약 기능을 통해 생산성을 높이는 것이 목표였습니다. - Cursor + Claude 조합을 통해 PRD로 활용 가능한 문서 초안을 빠르게 생성할 수 있었으며,
기존 수작업보다 시간을 절약하고 일관성을 높일 수 있었습니다.
Part 3 - 종합적으로 얻은 교훈
| 공통 포인트 | 테스트 리팩토링 | README 자동화 |
|---|---|---|
| 반복 제거 | 파라미터화(e.g., @pytest.mark.parametrize) |
워크플로우 정의(e.g., .taskmaster/docs/prd.txt 기반) |
| 구조화 | BaseTestData 패턴 도입 |
문서 초안 생성을 위한 .taskmaster/docs/prd.txt 기반 |
| 자동화 가능성 | pytest와 dataclass를 통한 테스트 데이터 관리 |
Claude와 MCP를 활용한 문서 초안 생성 |
| 협업 효율 향상 | 설명이 명확한 테스트 케이스 | 최신화된 문서 유지 |
Part 4 - 향후 개선 방향
테스트 측면
- AI를 활용한 테스트 코드 개선: AI를 통해 테스트 케이스를 자동 생성하거나, 코드 취약점 분석을 기반으로 테스트 시나리오를 제안하는 방안을 실험할 예정입니다.
- 실패 테스트 자동 수집 및 공유: CI/CD 파이프라인과 연동하여 실패한 테스트를 자동으로 수집하고, 정기적인 회고 시 자동으로 공유될 수 있도록 개선하고자 합니다.
문서 측면
- PR/커밋 과정에서의 README.md 자동 반영: Git Hooks나 CI/CD 파이프라인을 활용하여 커밋 또는 푸시 과정에서
README.md를 자동으로 업데이트하는 워크플로우를 실험할 예정입니다. - Changelog 자동 작성: 커밋 메시지를 기반으로 한 changelog 자동 작성 시스템 도입을 검토할 예정입니다.
Part 5 - 확장 실험 및 추가 통찰
테스트 커버리지 시각화
pytest-cov및coverage.py를 활용하여 테스트 커버리지를 측정하였습니다.- VS Code용 확장 프로그램(Coverage Gutters)을 통해 커버리지를 시각적으로 확인할 수 있었습니다.
- 리팩토링 이후 누락된 테스트 구간(blind spot)을 쉽게 파악하고 보완할 수 있었습니다.
- 향후에는 CI 상에서 커버리지 기준 미달 시 빌드가 실패하도록 설정할 예정입니다.
Part 6 - 다양한 테스트 클래스 패턴 확장
BaseTestData는 다양한 도메인 테스트에 적용할 수 있도록 설계되었습니다.- 예시:
UnverifiedListTestData,InvalidTokenTestData,ConditionByUserRoleTestData
- 예시:
- 공통 필드는 상속 구조를 통해 유지하며, 테스트 목적에 따라 유연하게 파라미터를 확장하였습니다.
Part 7 - 문서 편의성 향상의 확장 가능성
- 이번 실험은 문서 전체 자동화가 아닌, AI를 활용한 편의성 증대에 초점을 맞추었습니다.
- 향후 확장 가능성:
- PR 설명 초안 생성 (
git diff기반 요약) - API 문서 요약 자동화 (OpenAPI + docstring 기반)
- changelog 초안 자동 생성 (커밋 로그 기반)
- PR 설명 초안 생성 (
- Claude와 MCP 조합은 반복적인 문서 작성/정리에 있어 매우 유용한 도구로 평가됩니다.
Part 8 - 참고 환경
- 테스트:
pytest, FastAPI, SQLAlchemy, MariaDB - 자동화:
Cursor,Claude,Task Master (MCP) - 구성 예시:
tests/test_*.py– 구조화된 파라미터 기반 테스트.taskmaster/docs/– 문서 자동화 입력 파일 디렉토리
Part 9 - 마무리
개발자는 “코드를 잘 작성하는 능력”뿐만 아니라,
테스트와 문서라는 커뮤니케이션 도구를 정비하는 역량도 중요하다고 생각합니다.
이번 실험을 통해 작은 리팩토링과 자동화가
협업과 유지보수 환경을 개선하는 데 있어 큰 차이를 만들 수 있음을 체감하였습니다.

