R&D
개발현황
EQ-1 솔루션 내 DuckDB 도입 타당성 검토: 정혜성 연구원
-
 관리자
관리자
- 2025.07.15
EQ-1 솔루션 내 DuckDB 도입 타당성 검토
작성일시 : 2025년 6월 26일 목요일
작성자 : 정혜성
1. 들어가며
EQ-1은 크레플이 개발한 비전 검사 솔루션으로, 다양한 산업 현장에서 검사 공정의 자동화에 활용되고 있습니다.
현재 EQ-1 시스템은 검사 설정 관리 및 결과 기록 관리 등을 위해 관계형 데이터베이스를 사용하고 있습니다.
최근에는 경량 분석용 데이터베이스로 주목받고 있는 DuckDB를 시스템에 도입해보자는 의견이 제기되었으며,
이에 따라 DuckDB의 기술적 특징과 성능, 그리고 기존 EQ-1 구조와의 연계 가능성을 종합적으로 검토하였습니다.
본 기술노트에서는 검토 과정에서 파악한 주요 기술적 내용과 새로운 지식들을 정리하고, 비전 검사 시스템에 DuckDB를 활용하는 것이 합리적인 선택인지에 대한 근거를 제시하고자 합니다.
2. DuckDB 한 줄 요약
DuckDB is an in-process SQL OLAP database management system.
공식 홈페이지를 비롯해 매뉴얼, 기술 블로그 등 다양한 자료를 조사한 결과,
위 문장이 DuckDB의 특성을 가장 간결하고 정확하게 설명한 표현이라 판단하였습니다.
이 글을 끝까지 읽고 나면 이 문장이 어떤 의미인지 자연스럽게 이해하실 수 있을 것입니다.
3. 왜 DuckDB가 유명해졌을까?

기술을 검토할 때 저는 습관적으로 ‘왜 이런 이름을 가졌는지’, ‘왜 사람들에게 인기있는지’를 먼저 찾아보는 편입니다.
DuckDB가 주목받게 된 배경에는 BIG DATA IS DEAD라는 선언이 있습니다.
Google BigQuery를 개발했던 Jordan Tigani가 발표한 이 선언은 다음과 같은 현실을 지적하고 있습니다.
- 대부분의 기업은 실제로 ‘빅데이터’를 보유하고 있지 않음
- 데이터를 분석하는 사용자도 전체 데이터를 대상으로 쿼리하지 않음
- 과거에는 분산 처리가 필요했던 작업도 이제는 단일 머신에서 충분히 가능함
- 데이터는 사실 자산이 아닌 부채일 수 있음
이러한 흐름 속에서 DuckDB는 복잡한 분산 시스템 없이도 빠르고 유연하게 분석 작업이 가능한 실용적인 대안으로 부상하게 되었습니다.
4. 왜 하필 이름이 오리일까?
공식 홈페이지에는 이름의 유래에 대한 명확한 설명이 없지만, 비교적 자세한 내용을 dbdb.io에서 확인할 수 있었습니다.
History
DuckDB was created in response to the need for a high-performing, analytical DBMS that could be easily embedded within other processes, specifically targeting data science workloads. The project was initiated in 2018 by Mark Raasveldt, a PhD student from CWI, and his supervisor Hannes Mühleisen. Although not heavily involved in the codebase of DuckDB, Peter Boncz, the inventor of Vectorwise, provided valuable advice and insights to the creators. They were inspired by the fact that many data scientists were re-implementing database systems using Python and R, which could be greatly improved by incorporating research in database fields such as optimizer and parallelism.
The core idea behind DuckDB was to retain the simplicity and ease-of-use of SQLite, while enhancing it with fast analytical processing and fast data transfer between R/Python and the RDBMS for OLAP workloads.
The project was named "DuckDB" because the creators believed that ducks were resilient and could live off anything, similar to how they envisioned their database system operating. Additionally, Hannes had a pet duck named Wilbur who inspired the name.
마지막 문단에서 볼 수 있듯이 ‘DuckDB’라는 이름은 오리처럼 어떤 환경에서도 살아남는 유연하고 강인한 시스템이 되기를 바라는 마음에서 지어졌습니다.
또한, 공동 개발자 Hannes가 키우던 애완오리 Wilbur도 이름의 영감이 되었다고 합니다.
생각해보면, 오리는 육지에서는 걷고, 물 위에서는 헤엄치며, 하늘에서는 날 수 있는 동물입니다.
이처럼 다양한 환경에 자연스럽게 적응하는 오리의 특성은, DuckDB가 지향하는 기술 철학과도 맞닿아 있습니다.
DuckDB는 단일 파일 기반의 경량 구조, 높은 이식성, 그리고 다양한 실행 환경에서의 안정성을 바탕으로 유연하게 동작하는 분석형 데이터베이스를 목표로 합니다.
이러한 철학이 ‘Duck’이라는 이름에도 자연스럽게 반영되어 있다고 볼 수 있습니다.
로고도 귀엽고 단순한 오리 모양으로 구성되어 있습니다
![]()
5. 공식문서에서 소개하는 DuckDB 장점들
DuckDB는 단일 실행 파일로 작동하는 경량 분석용 데이터베이스로, 설치와 사용이 간편하면서도 고성능 분석 기능을 제공합니다.
공식 문서에서 강조한 DuckDB의 주요 장점은 다음과 같습니다:
| 항목 | 설명 |
|---|---|
| Simple | 설치 및 배포가 매우 간편합니다. 외부 의존성이 없고, 호스트 애플리케이션 내에서 in-process로 실행되거나 단일 바이너리로 동작합니다. |
| Portable | Linux, macOS, Windows, Android, iOS 등 다양한 운영체제와 하드웨어 아키텍처에서 실행 가능하며, Python, R 등 주요 언어에 대한 API를 제공합니다. |
| Feature-rich | SQL 문법이 풍부하며, CSV, Parquet, JSON 등 다양한 포맷을 읽고 쓸 수 있습니다. 로컬 파일뿐 아니라 S3와 같은 원격 저장소도 지원합니다. |
| Fast | 컬럼 기반 엔진과 병렬 처리 기능을 통해 고속 분석 쿼리를 실행할 수 있으며, 메모리보다 큰 데이터셋도 처리 가능합니다. |
| Extensible | 사용자 정의 함수, 새로운 데이터 타입 및 파일 포맷, SQL 확장 등을 지원하며, 커뮤니티 기반의 확장 기능도 사용할 수 있습니다. |
| Free | MIT 라이선스 기반의 오픈소스로 제공되며, 핵심 프로젝트와 확장 기능 모두 무료로 사용할 수 있습니다. DuckDB Foundation이 지적 재산권을 보유하고 있습니다. |
이 장점들을 종합하면, DuckDB는 가볍지만 강력한 분석 환경을 원하는 사용자에게 매우 적합한 선택지라 할 수 있습니다.
특히 Python, R 기반의 데이터 사이언스 환경이나 경량 서버 사이드 분석 도구로써 큰 장점을 제공합니다.
6. 벤치마크로 보는 DuckDB
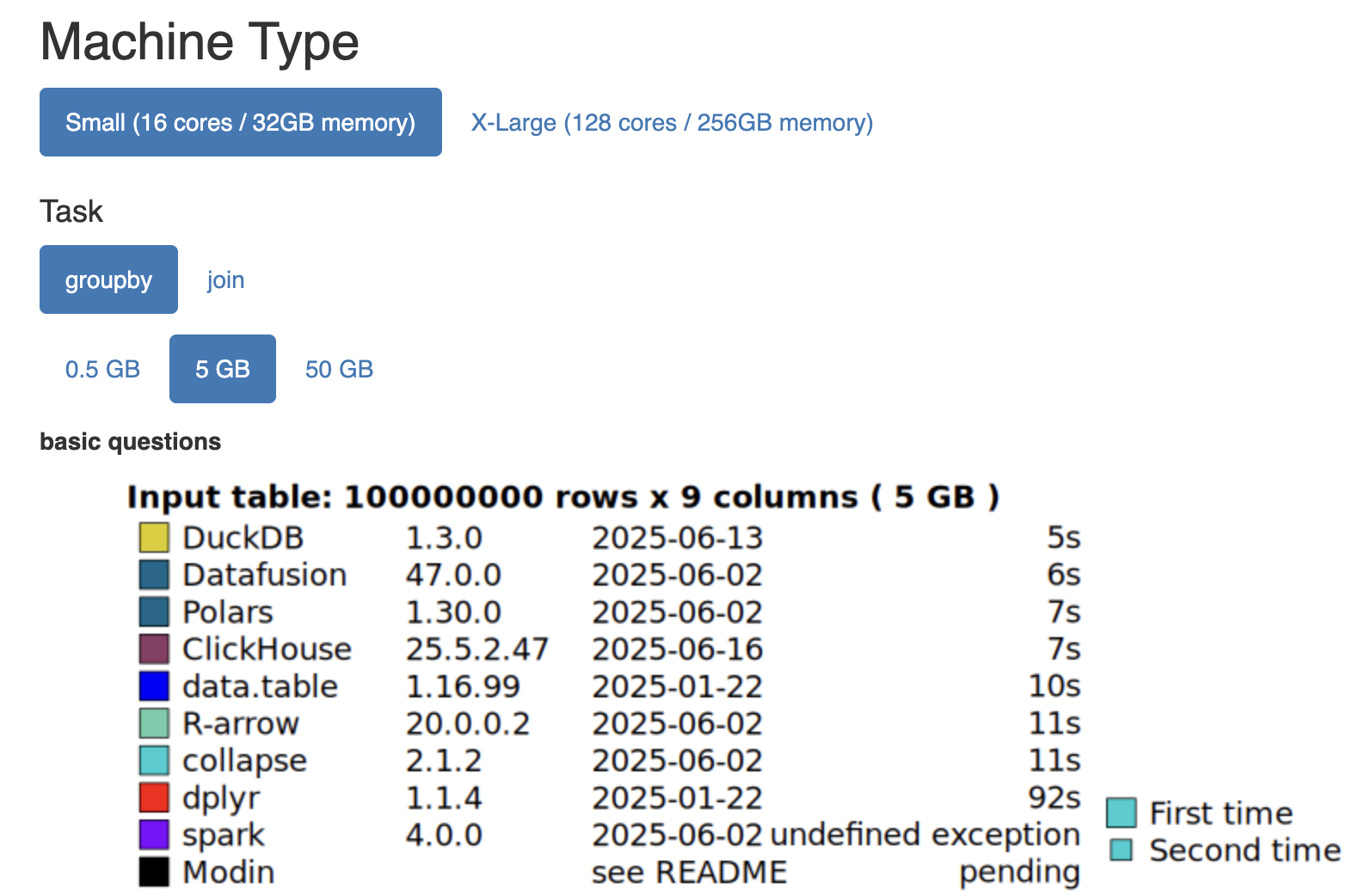
DuckDB에서 공개한 벤치마크 문서 Database-like ops benchmark에 따르면, DuckDB는 GROUP BY, JOIN 등 대표적인 분석 쿼리에서 매우 우수한 성능을 보여주고 있습니다.
조합에 따라 세부 순위는 조금씩 달라지지만, 대부분의 경우 DuckDB는 항상 상위권에 위치하며 안정적인 성능을 유지합니다.
다만 이 벤치마크는 분석에 특화된 데이터베이스 간의 비교를 중심으로 구성되어 있다는 점을 고려해야 합니다.
7. 간단한 설치와 실행
공식 문서에서도 언급했듯이, DuckDB는 설치 및 배포가 매우 간편합니다.
설치 가이드를 참고하면 운영체제와 환경에 맞는 CLI 버전, Python 패키지 등 다양한 방식으로 설치할 수 있습니다.
저는 맥북에서 CLI로 설치를 했습니다.
설치가 완료되면 터미널에서 duckdb 명령어를 입력하여 즉시 실행할 수 있습니다.
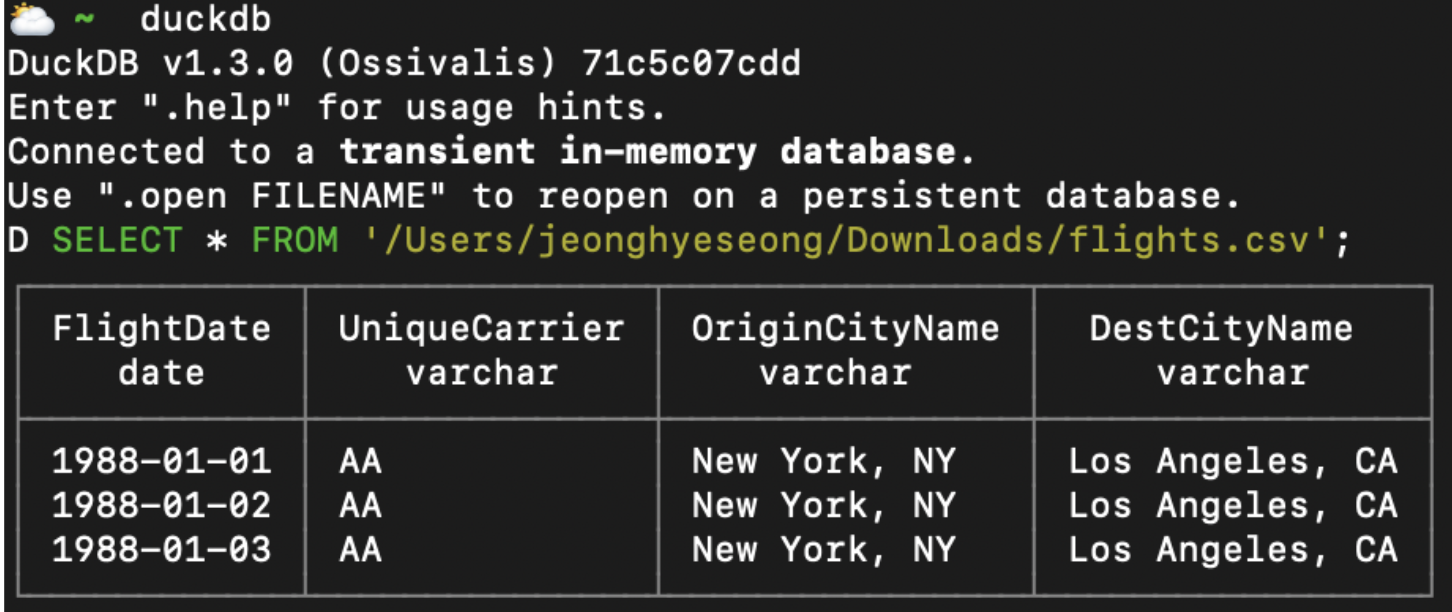
CLI 환경에서도 SQL 쿼리를 직접 실행할 수 있으며, CSV/Parquet 파일 등을 바로 불러와 분석하는 데에도 사용할 수 있습니다.
8. EQ-1 에서 사용중인 DB 와 비교
지금까지는 DuckDB에 대한 이해를 중심으로 살펴보았습니다.
이제부터는 실제로 EQ-1 시스템에 DuckDB를 도입할 수 있을지를 검토하기 위해, 기존 시스템에서 사용 중인 데이터베이스 구조를 먼저 정리해보았습니다.
EQ-1 솔루션은 프로젝트별로 사용 중인 DB가 다소 상이하며, SQLite와 MariaDB 두 가지가 주로 사용되고 있습니다.

SQLite는 전 세계적으로 가장 널리 사용되는 임베디드형 관계형 데이터베이스 중 하나입니다.
DuckDB 역시 초기 개발 철학에서 SQLite를 참고하여, “SQLite for analytics”를 지향하는 경량 분석용 데이터베이스를 목표로 개발되었습니다.
EQ-1 시스템에서는 주로 단일 장비 기반의 검사 장비에서 SQLite를 사용하고 있으며, 로컬 환경에서 독립적으로 동작합니다.
검사 결과를 장비 내부에 저장하거나 간단히 조회하는 용도로 활용되고 있으며, 서버나 네트워크와 연결되지 않아도 사용할 수 있다는 점에서 높은 안정성과 간편함을 제공합니다.
MariaDB는 네트워크 기반의 구조를 갖는 프로젝트에서 사용되고 있습니다.
복수의 장비 간 데이터 공유, 중앙 서버와의 통신, 사용자별 접근 제어 및 동시 처리 등 트랜잭션 처리와 병렬성이 요구되는 상황에 적합한 관계형 데이터베이스입니다.
이렇듯 SQLite와 MariaDB는 서로 목적과 장단점에 분명한 차이가 있습니다.
DuckDB 역시 마찬가지로 고유한 특징과 철학을 가지고 있으며, 기존 시스템에 도입하기 위해서는 이 세 가지 데이터베이스 간의 구조적 차이를 명확히 비교해볼 필요가 있습니다.
아래는 핵심 특징만 간추려 SQLite, DuckDB, MariaDB를 비교 정리한 표입니다.

주요 내용은 아래와 같습니다.
DuckDB는 SQLite와 마찬가지로 프로그램 내에서 함께 실행되는 In-Process 방식의 데이터베이스입니다.
별도의 서버 없이 애플리케이션과 동일한 프로세스에서 동작하며, 가볍고 빠른 초기화를 지원합니다.DuckDB의 데이터는 모두 단일 파일로 관리됩니다.
이는 SQLite와 동일한 구조로, 배포와 백업, 이식성 측면에서 유리한 장점을 가집니다.저장 방식 측면에서는 SQLite와 MariaDB가 Row 기반인 반면, DuckDB는 Column 기반 저장 구조를 사용합니다.
따라서 분석 중심 쿼리에서 더 높은 성능과 압축 효율을 기대할 수 있습니다.DuckDB는 동시성 처리 측면에서는 제한이 있습니다.
DuckDB는 Multi-Process 환경에서 읽기(Read-Only) 모드만 지원하며, 동시에 여러 프로세스에서 쓰기 작업은 불가능합니다.
잠깐! OLTP, OLAP 그리고 저장 방식의 차이
EQ-1 시스템에서 사용 중인 SQLite, MariaDB, DuckDB는 각각 서로 다른 목적과 저장 방식을 지닌 데이터베이스입니다.
이 차이를 이해하기 위해서는 먼저 OLTP vs OLAP, 그리고 행 기반 vs 열 기반 저장 구조에 대한 이해가 필요합니다.
OLTP (Online Transaction Processing)는 실시간 트랜잭션 처리에 최적화된 시스템을 의미합니다.주요 특징은 다음과 같습니다:
- 데이터의 삽입, 수정, 삭제가 빈번하게 일어남
- 짧고 빠른 쿼리가 반복적으로 실행됨
- 일반적으로 행(Row) 기반 저장 구조를 사용
- 예: MariaDB, SQLite
EQ-1의 장비 중 일부는 검사 결과를 실시간으로 기록하고 관리해야 하므로 OLTP 구조의 데이터베이스가 적합합니다.
OLAP (Online Analytical Processing)는 대용량 데이터를 분석하거나 통계를 집계하는 데 최적화된 구조입니다.주요 특징은 다음과 같습니다:
- 대량의 데이터를 대상으로 한 복잡한 조회 쿼리 수행
- 집계, 필터, 그룹핑 중심의 분석에 적합
- 일반적으로 열(Column) 기반 저장 구조를 사용
- 예: DuckDB, ClickHouse
DuckDB는 OLAP용 경량 DB로, 트랜잭션보다는 읽기 중심의 분석 업무에 적합합니다.
그럼 "행 기반 저장", "열 기반 저장"은 무슨 의미일까요?
말 그대로 데이터를 어떻게 저장하느냐에 따른 구조상의 차이입니다.
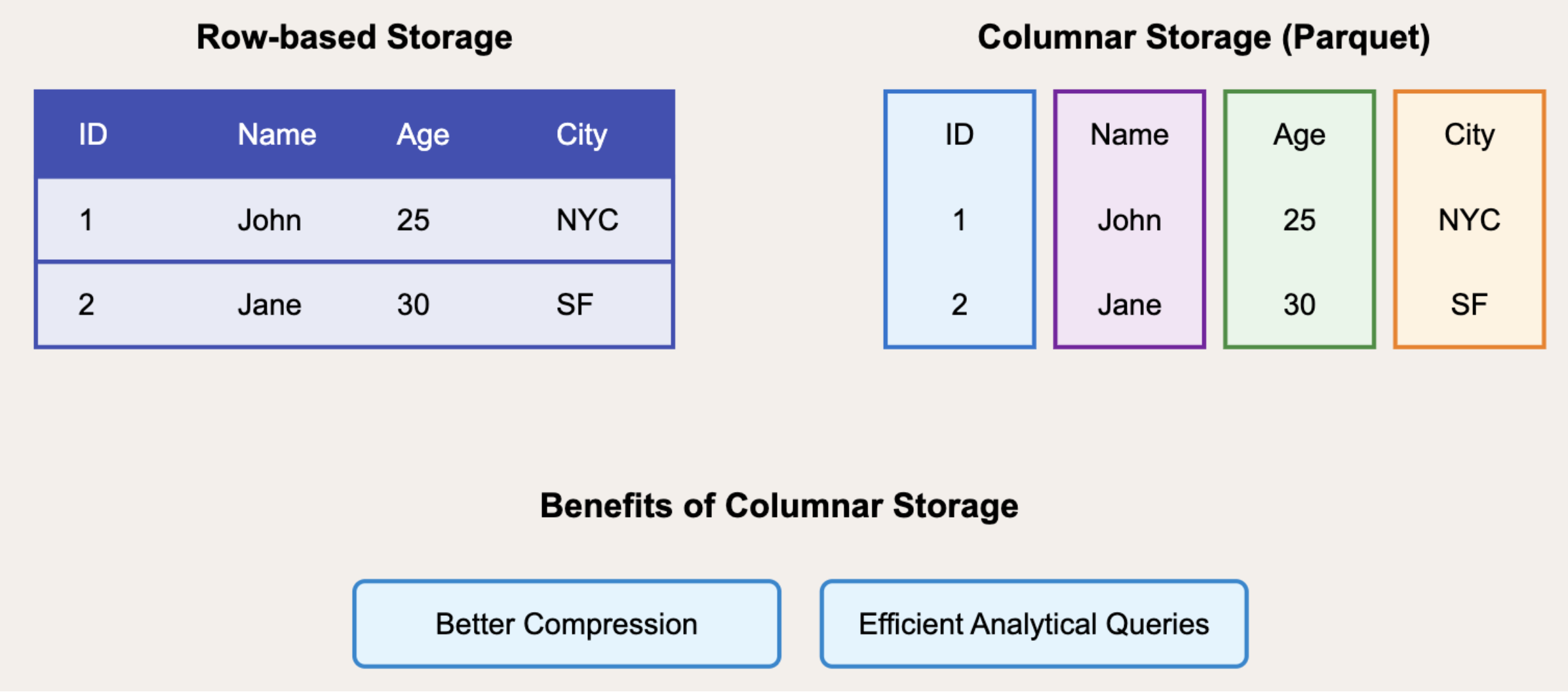
아래 그림을 보면 한눈에 이해할 수 있습니다.
행 기반 저장(Row-Based Storage)은 한 사람(또는 한 검사 결과)의 모든 컬럼 값을 한 덩어리로 저장합니다.
→ 삽입, 수정, 삭제가 빠르며, OLTP에 적합합니다.
열 기반 저장(Column-Based Storage)은 같은 컬럼끼리 묶어서 저장합니다 (예: 이름만 쭉, 나이만 쭉).
→ 컬럼 단위 연산(평균, 합계 등)에 유리하며, 압축 효율도 뛰어남.
→ OLAP 환경에 적합합니다.
9. EQ-1에 DuckDB를 도입하기 위해 고려해야할 점
앞서 정리한 DuckDB의 구조적 특징과 기존 EQ-1 시스템과의 차이를 바탕으로,
실제 도입 시에는 반드시 사전에 검토해야 할 기술적 이슈들이 존재합니다.
그중에서도 특히 중요한 두 가지 이슈를 아래와 같이 정리하였습니다.
9-1. 쓰기 빈도가 많은 환경에서 열기반 스토리지의 효율성 문제
DuckDB는 열(Column) 기반 저장 구조를 사용하여, 대량 데이터를 대상으로 한 고속 분석 및 집계 연산에 매우 강점을 보입니다.
그러나 이러한 구조는 쓰기 작업(INSERT, UPDATE)이 자주 발생하는 환경에서는 성능 저하를 유발할 수 있습니다.
EQ-1 시스템의 일부 장비는 검사 결과를 실시간으로 지속적으로 기록해야 하며,
이처럼 쓰기 중심의 워크로드는 DuckDB의 설계 철학과는 다소 맞지 않을 수 있습니다.
열 기반 저장 구조는 같은 컬럼끼리 데이터를 묶어 저장하므로,
새로운 행을 추가하거나 특정 행을 갱신할 때 복잡한 메모리 재배치 및 디코딩이 필요하게 됩니다
DuckDB의 공식 문서에서도 반복적인 단일 행 삽입은 비효율적일 수 있으며, Bulk Insert 방식으로 처리할 것을 권장하고 있습니다.

또한 Lukas Barth 벤치마크에 따르면,
단일 행 삽입 처리 시간에서 SQLite가 DuckDB보다 훨씬 우수한 성능을 보이는 것을 확인할 수 있습니다.
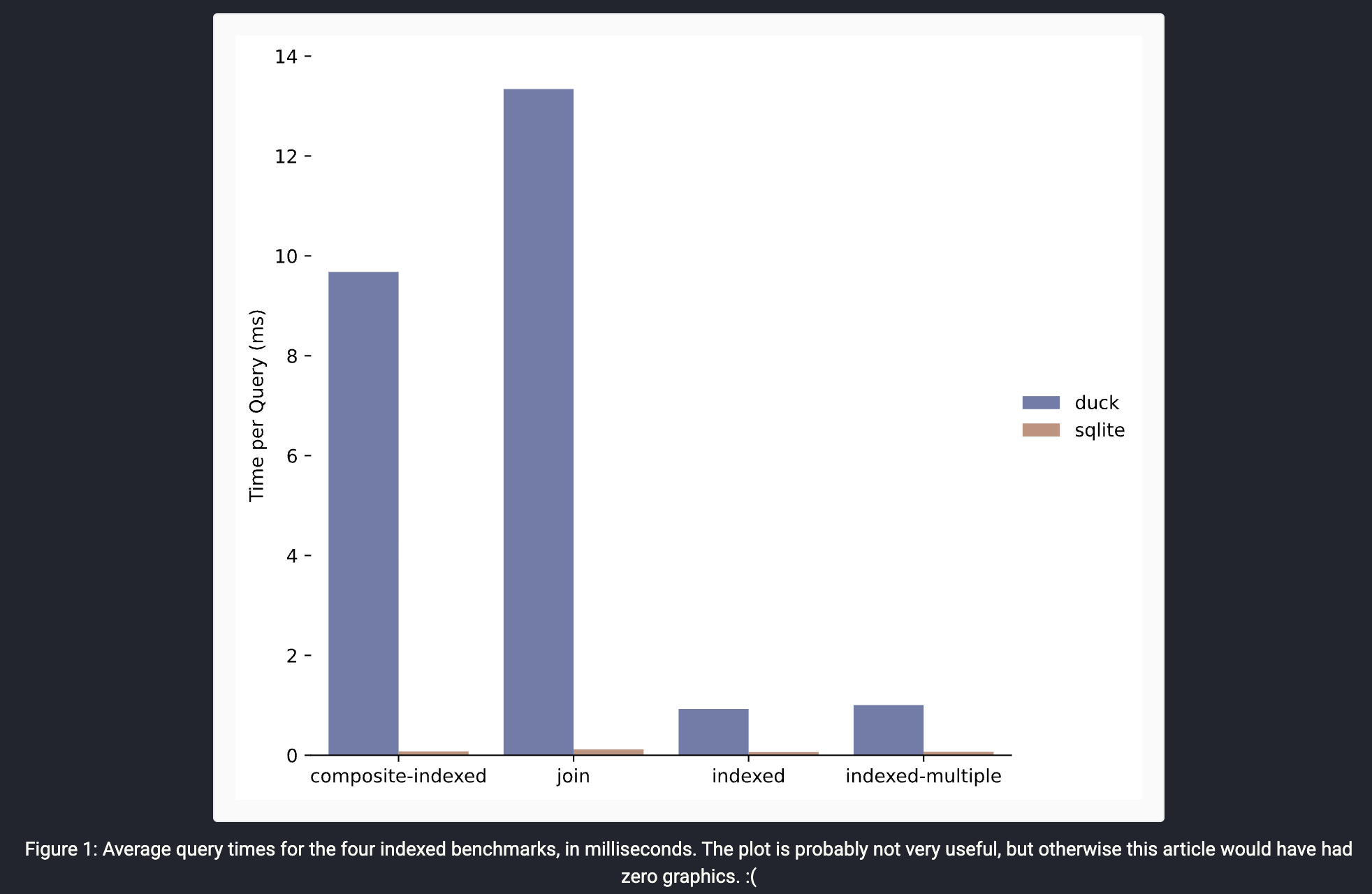
이처럼 쓰기 빈도가 높은 환경에 DuckDB를 그대로 적용할 경우,
지속적인 성능 저하, 쿼리 지연, 파일 크기 증가 등의 문제가 발생할 수 있습니다.
EQ-1처럼 주기적 기록이 핵심인 장비에는 신중한 도입 검토가 필요합니다.
Python으로 DuckDB vs SQLite 쓰기 성능 비교
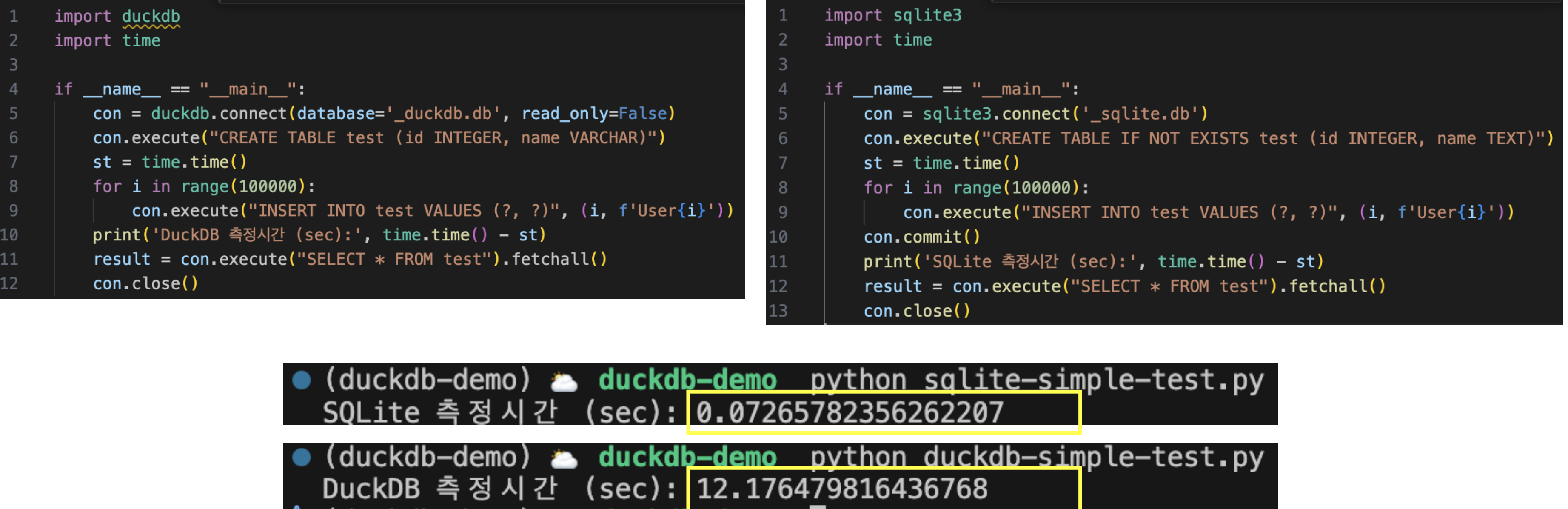
앞서 살펴본 열 기반 DB의 쓰기 성능 이슈가 실제 환경에서 어느 정도 영향을 미치는지 확인하기 위해, Python 환경에서 DuckDB와 SQLite의 단일 행 반복 삽입 처리 속도를 간단히 비교해보았습니다.
동일한 조건에서 10만 건의 레코드를 삽입한 결과는 다음과 같습니다.
- SQLite: 약 0.07초
- DuckDB: 약 12.17초
무려 12초 이상의 차이가 발생하며, DuckDB의 쓰기 성능이 확연히 떨어지는 것을 확인할 수 있었습니다.
추가로, 비록 속도는 느리지만 앞서 열기반 저장방식이 데이터 압축 효율이 높다는 점을 언급했듯,
실제로 DuckDB로 저장한 파일 크기가 SQLite에 비해 약 3배 정도 작은 것을 확인할 수 있었습니다.
- SQLite: 약 2.1MB
- DuckDB: 약 0.8MB

9-2. 동시성 제약 (Read Only Multi-Process)
DuckDB는 멀티 프로세스 환경에서 읽기만 지원하며, 동시 쓰기를 지원하지 않습니다.
DuckDB 공식 문서에서도 동시성 지원에 대한 제약을 명시하고 있으며, 다음과 같은 내용을 확인할 수 있습니다.

이로 인해, 아래와 같은 상황에서는 사용에 제약이 생길 수 있습니다:
- 복수의 프로세스 또는 모듈이 동시에 데이터를 기록해야 하는 환경
- 클라이언트와 서버가 분리되어 비동기적으로 DB를 접근하는 구조
- 백그라운드에서 지속적으로 데이터를 기록하고, 동시에 UI에서 읽어야 하는 상황 등
EQ-1 시스템은 여러 개의 UI, 컨트롤 모듈, 검사 모듈, 중앙 서버 등이 병렬로 동작하면서 비동기적으로 데이터를 주고받기 때문에, 이런 구조에서는 동시성 제약이 큰 한계로 작용할 수 있습니다.
이러한 구조에서 DuckDB를 그대로 도입할 경우, 다음과 같은 문제가 발생할 수 있습니다:
- 동시 쓰기 중 충돌 또는 실패
- 프로세스 간 동기화 로직을 별도로 구현해야 하는 부담
- 쓰기 병렬화가 어려워지는 구조적 한계
따라서 DuckDB는 단일 사용자, 단일 프로세스 중심의 분석 전용 서브 시스템에는 적합할 수 있지만, EQ-1과 같이 동시성과 병렬성이 요구되는 실시간 검사 시스템에서는 구조적 제약을 유의해야 합니다.
10. 결론
이번 검토를 통해 DuckDB의 기술적 구조와 설계 철학에 대해 깊이 있게 이해할 수 있었습니다.
특히 열 기반(columnar) 저장 방식이라는 개념을 새롭게 접하고, 분석형 데이터베이스의 설계 방식과 차별점을 체감할 수 있었습니다.
그러나 실제 EQ-1 시스템에 적용하기에는 몇 가지 제약이 분명했습니다.
쓰기 작업이 빈번하고, 다중 모듈에서 동시에 데이터를 기록해야 하는 EQ-1의 구조상,
DuckDB의 열 기반 구조와 단일 쓰기 처리 방식은 적합하지 않았습니다.
또한 기존에 사용 중인 SQLite 대비 확실한 도입 메리트를 찾기 어려웠고,
내부 논의 결과 역시 DuckDB는 도입하지 않는 방향으로 정리되었습니다.
결론적으로, DuckDB는 EQ-1 시스템의 메인 DB로는 적합하지 않지만,
향후 분석 전용 서브 시스템이나 리포트 생성 모듈과 같은 읽기 중심의 환경에서 제한적으로 사용할 수 있을 것이라 기대합니다.

