R&D
개발현황
이상탐지계의 괴물신인, UniNet 뜯어보기: 하승연 연구원
-
 관리자
관리자
- 2025.07.14
안녕하세요, 크레플 비전 파트의 하승연 연구원입니다. 저는 오늘 혜성처럼 등장한 Anomaly Detection 괴물신인 UniNet에 대해서 소개하고자 합니다.
오늘은 정확한 수식보다는 아 ~ UniNet이라는 아키텍처가 이렇게 생겼구나. 실험 결과는 어떻구나 ~ 정도로 이해해주시면 좋을 것 같습니다!
우선 이 주제를 선정한 이유는 저의 리더님인 전명중 연구소장님의 이야기 해주신 부분도 있고 papers with code 에서 여러 데이터 셋에 대해 상위권을 찍었다더라구요. 그래서 아 이 논문은 리뷰할만 하다. 라는 마음으로 선정하게 되었습니다.
UniNet 이름의 뜻
UniNet은 Unified Network의 줄임말로, 기존에 도메인마다 따로 만들어야 했던 이상탐지 모델을 하나로 통합(unified)해서 학습하고 사용할 수 있도록 만든 범용적인 이상탐지 프레임워크입니다.
즉, 산업용, 의료용, 비디오 이상탐지 등 다양한 환경을 하나의 모델로 커버할 수 있다는 점에서 UniNet이라는 이름이 붙었습니다.
UniNet 등장 배경
기존 이상탐지(Anomaly Detection) 모델들은 다음과 같은 문제가 있었습니다.
- 산업, 의료, 비디오 등 도메인마다 별도의 모델을 학습해야 했음
- 사전 학습(pre-trained)된 모델의 편향(Bias) 때문에 타겟 도메인에 잘 적용하지 못함
- 특히 도메인 간 feature 차이(domain gap) 때문에 한 모델로 다양한 영역을 처리하기 어려움
이러한 문제를 해결하기 위해 등장한 것이 UniNet입니다. UniNet은 contrastive learning과 feature selection 기법을 결합해, 다양한 도메인에 공통으로 적용 가능한 범용 이상탐지 프레임워크를 목표로 설계되었습니다.
결과적으로 산업/의료/비디오 등 11개 이상의 데이터셋에서 우수한 성능을 달성했고 CVPR 2025에 정식 채택되었으며, MVTec AD, BTAD, VisA 등 주요 벤치마크에서 1위를 기록했다고 합니다.
아키텍처 구성
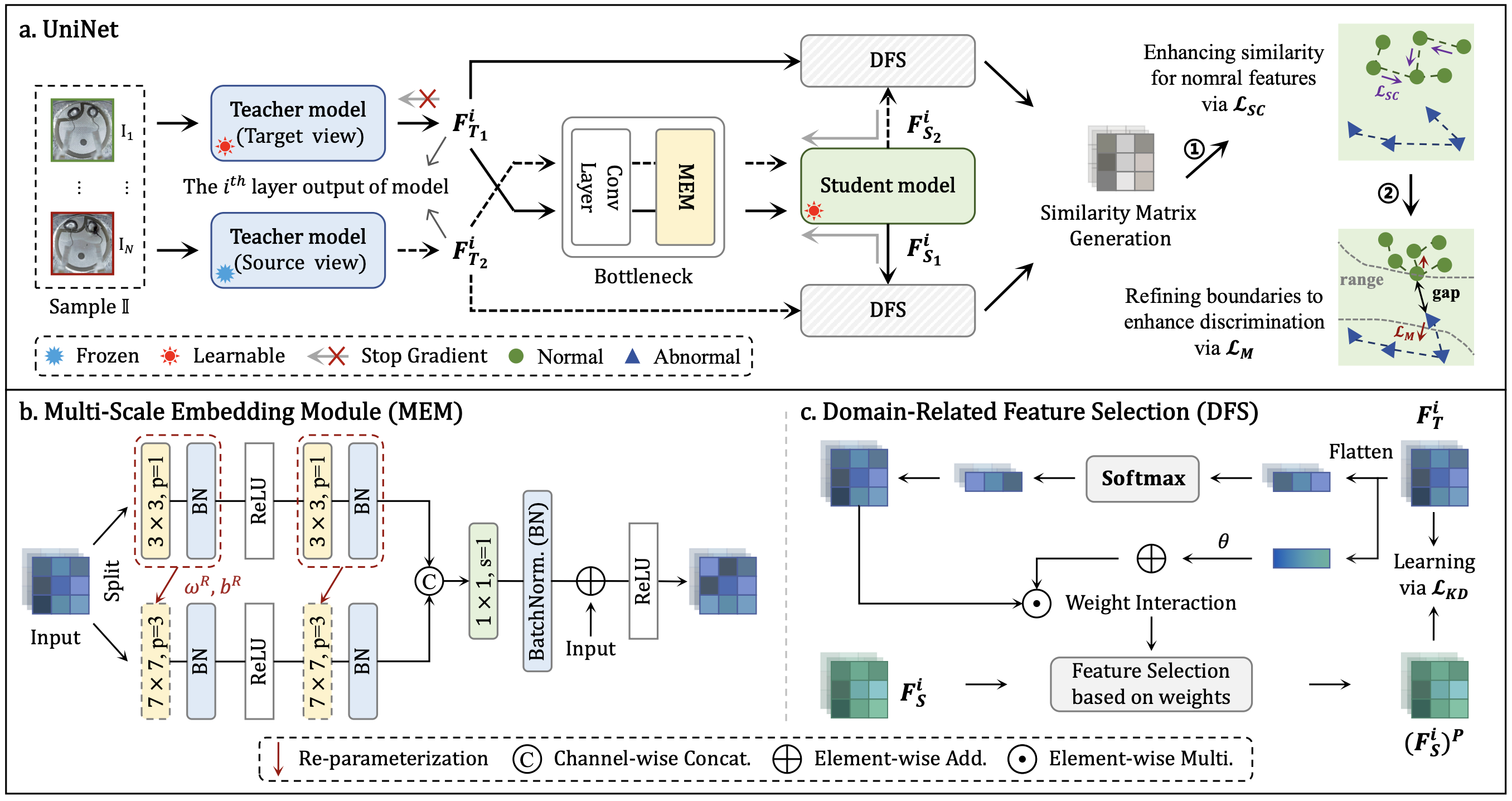
위의 목표를 달성하기 위해 UniNet은 다음과 같은 아키텍처로 구성됩니다.
- Student - Teacher
- BottleNeck
- MEM : Multi-scale Embedding Model (MEM)
- DFS : Domain Related Feature Selection
- LSC : Similarity-Contrastive Loss
- LM : Margin Loss
Student-Teacher 구조
UniNet의 근간은 학생-교사(Student-Teacher, S-T) 모델 구조입니다. 먼저 Teacher 모델은 이미지넷(ImageNet) 등 대규모 데이터로 사전 학습된 합성곱 신경망(논문에서는 WideResNet50 기반)을 사용하며, 학습 동안 고정되어 정상 패턴에 대한 기준 특징을 제공합니다.
Student 모델은 동일한 구조를 갖되 학습이 가능한 네트워크로, 초기에는 Teacher와 동일한 출력을 내지 못하지만, 학습을 통해 Teacher의 출력 특징을 모방하도록 훈련이 됩니다. 이 과정에서 각 계층에 대해 Teacher와 Student 출력 사이의 차이를 측정해 loss로 활용합니다. 정상 샘플의 경우는 차이가 작아야 할 것이고 이상 샘플의 경우 이러한 복제에 실패하여 차이가 발생하도록 설계되었습니다.
요약하면, Teacher는 정상 패턴의 지식을 제공하고 Student는 이를 학습하여 복원함으로써, 복원이 잘 안 되는 부분을 이상으로 간주하는 방식입니다. 이러한 S-T 구조는 기존에 나와있었던 ReContrast 라는 방법을 많이 참고해 변형한 것입니다. (논문 참고: https://arxiv.org/abs/2306.02602)
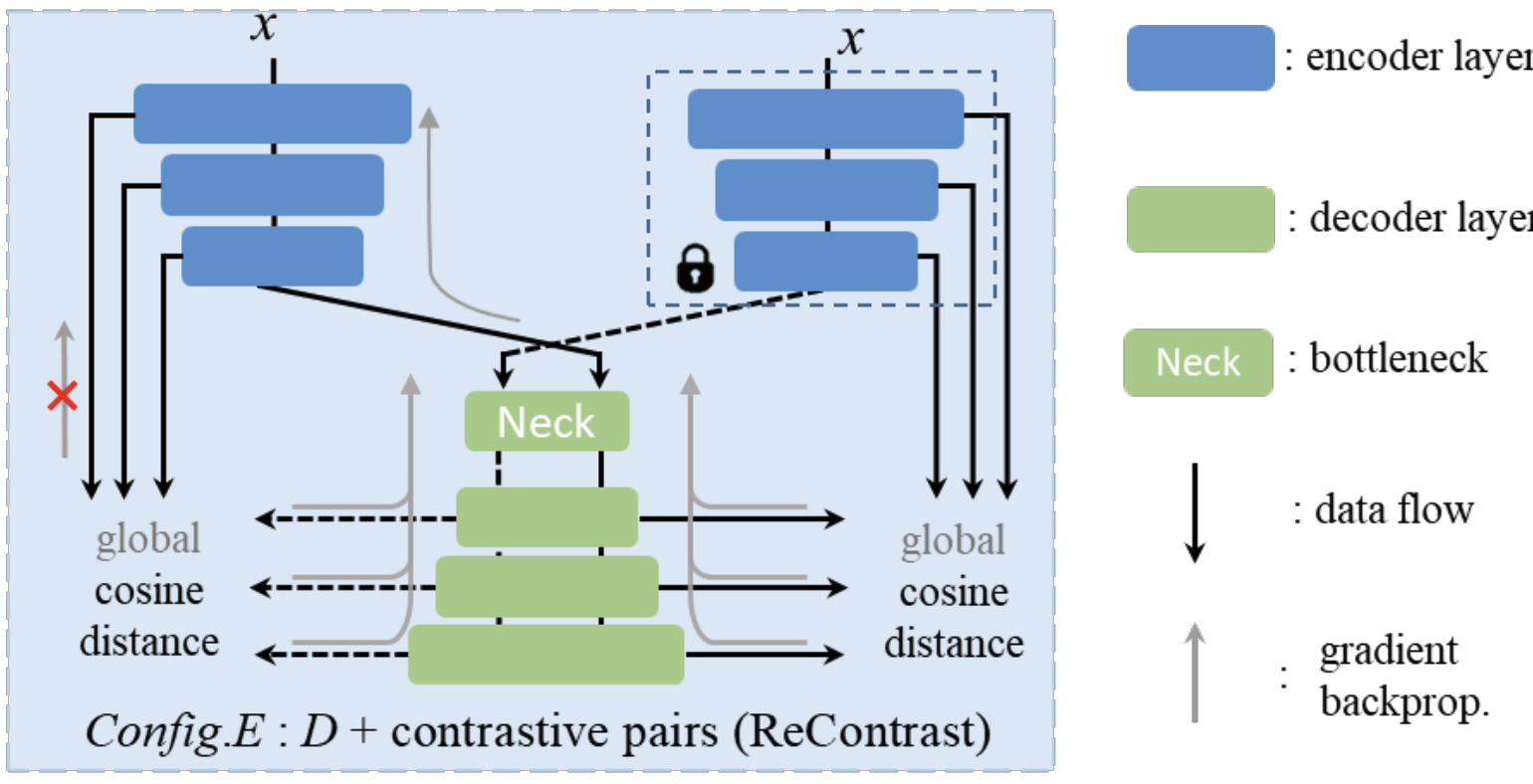
특히 UniNet에서는 하나의 이미지에 대해 두 종류의 Teacher를 활용하는데, 이를 타겟 뷰(Target view) Teacher와 소스 뷰(Source view) Teacher라고 부릅니다.
이는 같은 이미지에서 두 가지 서로 다른 증강(view)을 통과한 특징을 얻어 대조 학습에 활용하기 위함입니다.
두 Teacher는 동일한 모델이지만 입력에 서로 다른 변형을 가하여 두 가지 특징 맵을 추출하고 Student는 이러한 두 입력에 대해 각각 대응하는 출력을 내며, 최종적으로 Teacher와 Student 출력의 유사도를 비교하여 이상 여부를 판단합니다.
여기서 특징은 Target View 로 복원한 Student 결과는 Source View와 비교를 하고 Source View 로 복원한 Student 결과는 Target View와 비교를 합니다.
BottleNeck
BottleNeck은 Teacher와 Student를 이어주는 중간다리 역할을 합니다. UniNet에 있는 BottleNeck은 단순히 이어주는 역할만 하는 것이 아니라 추가적으로 하는 것이 있습니다.
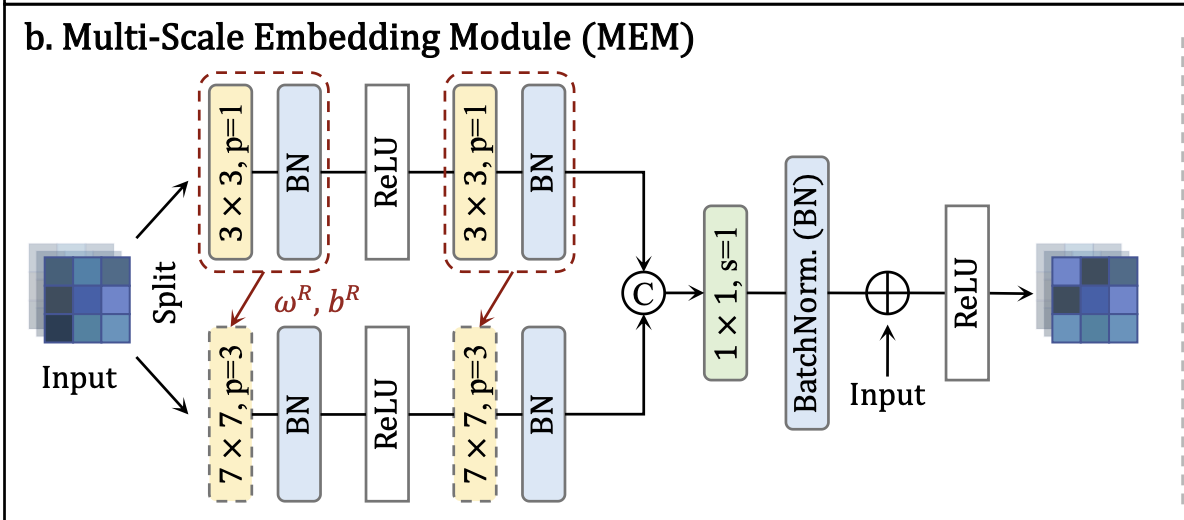
UniNet에서는 BottleNeck 내에서 MEM이라는 구조를 하나 추가했는데요, MEM은 Multi-scale Embedding Module 이라는 뜻을 가지고 있습니다. 기존의 방법들은 국소적인 패치 위주로만 학습하여 맥락 정보나 다중 스케일 정보를 충분히 활용하지 못하는 한계가 있었습니다. MEM은 특징 맵을 여러 갈래로 나누어 서로 다른 합성곱 커널 크기를 적용한 후 다시 합치는 구조를 가짐으로써 이런 문제를 해결하고자 했습니다.
위 그림에서 볼 수 있듯 입력을 두 갈래로 나누어 한 쪽에는 3X3 커널을, 다른 쪽에는 7X7 커널을 적용합니다. 각각의 경로 출력은 채널 방향으로 concatenation한 뒤 1X1 conv와 BatchNorm으로 융합합니다. 마지막으로 이 출력을 원래 입력 특징과 더해주는 residual connection을 적용하여, 여러 스케일의 정보를 보존하며 강화된 임베딩을 얻습니다.
MEM의 핵심 역할은 다양한 크기의 맥락 정보를 포착하여 학생이 보다 전반적인 관계를 이해할 수 있게 하는 것입니다. 예를 들어 산업 이미지의 경우 작은 스크래치부터 큰 패턴까지 이상 징후의 크기가 다양하고, 의료 영상 또한 국소 조직부터 장기 전체의 맥락이 중요할 수 있습니다. MEM을 통해 여러 패턴을 동시에 고려할 수 있어 성능이 향상됩니다. 이 논문의 뒤에 나오지만 실제로 실험에서 MEM을 제거하면 성능이 떨어지는 것으로 나타나, 이 모듈의 기여를 함을 확인하였습니다.
DFS
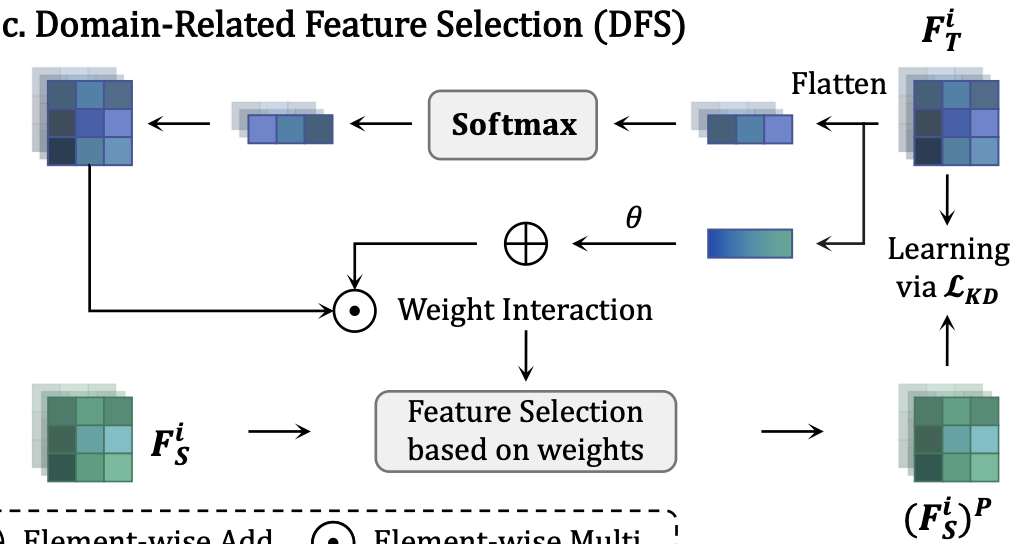
DFS는 Domain-related Feature Selection 라는 뜻을 가지고 있습니다. 이름 그대로 도메인에 따라 불필요한 feature를 제거하고, 의미 있는 feature만 선택하는 역할을 합니다.
그럼 대체 어떻게 선택할까요?
우선 DFS의 입력은 학생 특징과 교사 특징 두 개입니다. 저도 이 부분은 헷갈리기 때문에 입력부터 순차적으로 설명해보도록 하겠습니다.
- 교사 특징을 FTi를 flatten 하고 softmax를 통해 각 위치 (Pixel) 별 중요도 w을 계산합니다. A. 공간상 어디가 중요한지를 결정하는 로컬 가중치입니다.
- 교사 특징 FTi 각 채널의 평균을 구해서 어떤 특징이 전반적으로 중요할지를 판단합니다. A. 어떤 벡터에 집중할지 결정하는 전역 가중치입니다.
- 전역 가중치와 로컬 가중치를 곱해서 최종 가중치를 생성합니다.
- 학생 특징에 위에서 구한 가중치를 적용해 중요한 부분만 selection 할 수 있도록 합니다.
DFS의 효과는 도메인 간 불필요한 격차를 줄이고, 공통적으로 중요한 특징에 집중하게 만든다는 점입니다. 학생은 Teacher의 전체 정보를 다 따라하려다가 오히려 노이즈까지 학습하는 것을 피하고, 도메인 관련 핵심 정보만 효율적으로 학습하며 재구성하게 됩니다. 뒤의 실험에서도 아주 큰 차이는 아니지만 DFS를 적용한 경우가 제외한 경우보다 성능 향상이 됨을 보였습니다.
LSC : Similarity-Contrastive Loss
UniNet은 대조 학습(Contrastive Learning) 개념을 활용하여, 정상적인 특징은 최대한 서로 유사하게 만들고, 이상이 개입된 경우 유사도가 떨어지도록 학습합니다. 이를 담당하는 첫 번째 손실 항목이 LSC 입니다.
앞서 언급한 대로 하나의 샘플에서 두 개의 Teacher 특징 맵과 이에 대응하는 두 개의 Student 특징 맵을 얻을 수 있습니다. Teacher끼리-Student끼리 등의 조합으로 유사도 행렬을 계산합니다.
이렇게 얻은 유사도 행렬에서 대각선 요소끼리 (=같은 위치에 있는 특징끼리) 유사도를 1로 만드는 방향으로 정의됩니다. 구체적인 식은 다음과 같습니다.
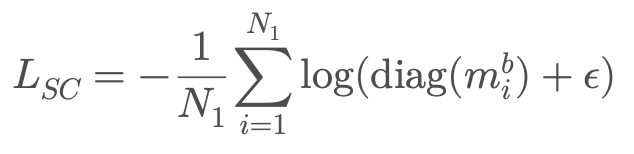
음.. 식을 한번 설명해보겠습니다.
우선 diag(m) 이부분이 대각 요소끼리의 유사도입니다. (S-T 유사도) 이 유사도를 1에 가까워지게 만든다고 했는데 1에 가까워질수록 log를 취했으니 저 값은 0에 가까워지겠죠. 손실이 작아진다는 건? > 좋다는 것입니다. 반대로 유사도가 작아지면 (0에 가까워지면) log를 취했을 때 값이 커지게 됩니다. 손실이 커진다는 것은? > 안 좋다는 것입니다.
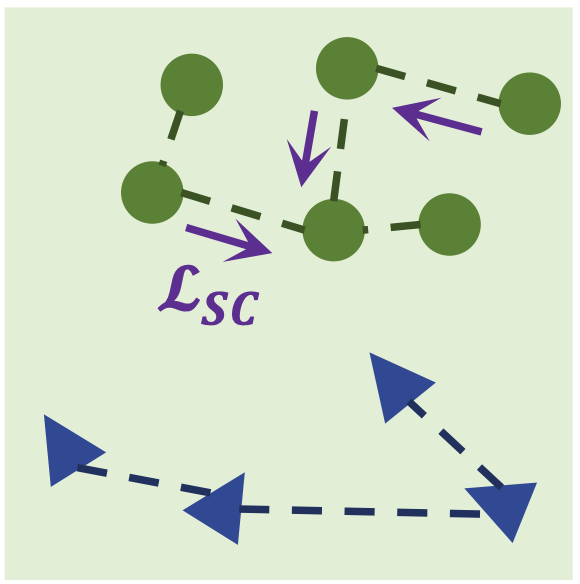
띠라서 S-T 유사도가 크면 클수록 loss는 작아지고, 유사도가 작으면 작을수록 loss는 커지게 되겠죠. 그래서 위 그림처럼 정상끼리의 분포가 저 촘촘해질 수 있습니다. 정상은 정상끼리 뭉치게!! 하기 위해서 이러한 loss 기법을 적용한 것입니다.
LM : Margin Loss
이 논문에서는 또 하나의 Loss 기법을 제안합니다. 바로 마진 손실 LM입니다. LM은 LCS를 이용해 1차적으로 유사도를 높인 정상 특징들에 대해 추가적인 분리(separation)를 하는 두 번째 손실입니다. 즉, 정상 그룹은 일정 수준 이상 더욱 뭉치게 하고, 이상 그룹은 정상과 명확히 구분되도록 거리를 벌리는 역할을 합니다. 어떻게 하는지 한 번 보도록 하겠습니다!
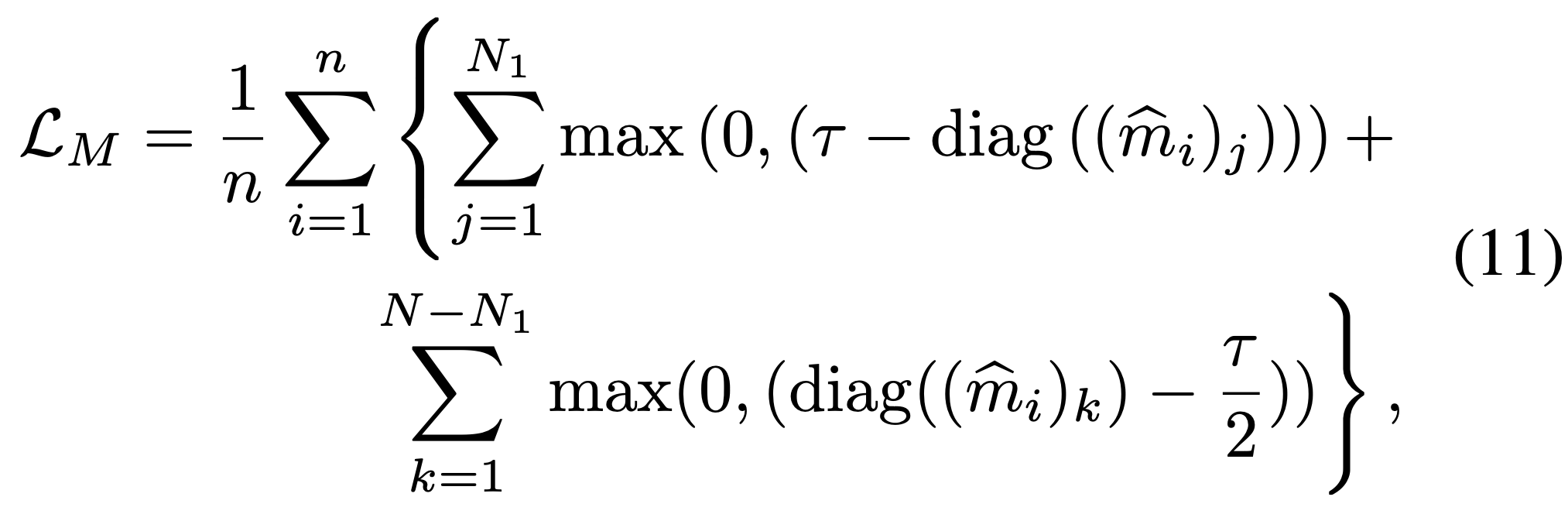
우선 수식은 이렇게 생겼습니다.
어우 길구요. 천천히 살펴보겠습니다.
첫 번째 항부터 살펴보도록 할게요. 먼저 위에서 설명했지만 diag(..)는 같은 위치의 S-T 유사도를 표현한 것이라고 했습니다. 유사도가 ![]() 보다 작으면 양수,
보다 작으면 양수, ![]() 보다 크면 음수가 됩니다. 0을 기준으로 최대값을 고르니깐 유사도가 크면 0이 채택 될거고, 아니면 뒤에 것이 채택되겠네요. 작으면? loss 가 낮다는 거니깐? 좋다는 겁니다. 이 항은 유사도가 작으면 패널티를 주는 항이라고 봐주시면 좋을 것 같습니다.
보다 크면 음수가 됩니다. 0을 기준으로 최대값을 고르니깐 유사도가 크면 0이 채택 될거고, 아니면 뒤에 것이 채택되겠네요. 작으면? loss 가 낮다는 거니깐? 좋다는 겁니다. 이 항은 유사도가 작으면 패널티를 주는 항이라고 봐주시면 좋을 것 같습니다.
- 유사도가
 보다 낮은 정상 샘플은 더 닮도록 학습시킨다 !!
보다 낮은 정상 샘플은 더 닮도록 학습시킨다 !!
뒤의 항을 살펴보도록 할게요. 여기서의 S-T 유사도는 이상 샘플일 때 입니다. 이상 샘플이면 유사도가 낮아야 합니다. 여기서 유사도가 ![]() 보다 작아지면? 음수가 되기 때문에 0이 채택될 거고 S-T 유사도가
보다 작아지면? 음수가 되기 때문에 0이 채택될 거고 S-T 유사도가 ![]() 보다 커지면 양수이기 때문에 패널티가 부과됩니다. 따라서 여기서는 유사도가 높을 수록 패널티를 부과합니다.
보다 커지면 양수이기 때문에 패널티가 부과됩니다. 따라서 여기서는 유사도가 높을 수록 패널티를 부과합니다.
- 이상 샘플은 유사도를
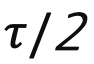 이하로 떨어뜨리도록 유도 !!
이하로 떨어뜨리도록 유도 !!
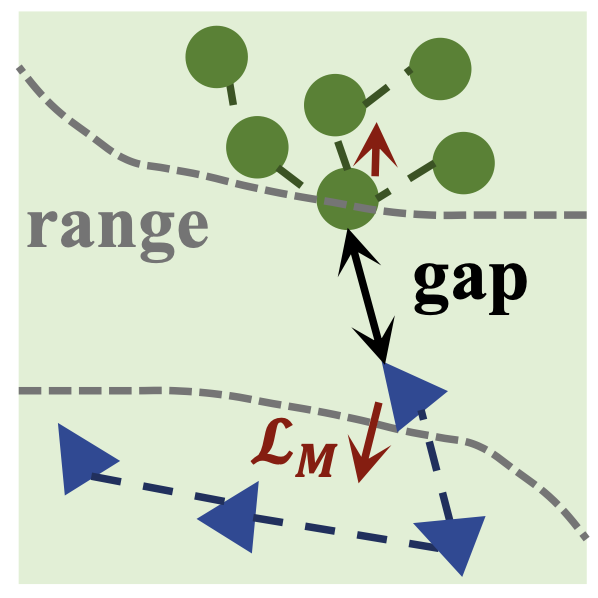
따라서 위 그림처럼 정상은 아주 뭉치게 이상은 확실히 분리되게 만들어줍니다.
이 과정을 통해 이상과 정상은 분포가 두 그룹으로 확실히 갈리는 sharp 경계가 생겨서
이게 결국 이상 탐지 성능 향상으로 이어지게 되는 것입니다.
다시 아키텍처로 돌아가서
자, 이렇게 UniNet에서 제안하는 핵심 구조들을 살펴보았습니다.
이제 이 아키텍처들이 실제로 얼마나 성능에 기여했는지, ablation 실험 결과를 기반으로 정리해보겠습니다.
Ablation Study: 무엇이 성능 향상에 기여했을까?
UniNet 논문에서는 다양한 구성 요소의 효과를 검증하기 위해 Ablation Study를 수행했습니다. 여기서는 핵심 구성 요소들을 하나씩 제거해가며 성능이 어떻게 변하는지를 확인했습니다.
실험 결과를 요약하면 다음과 같습니다:
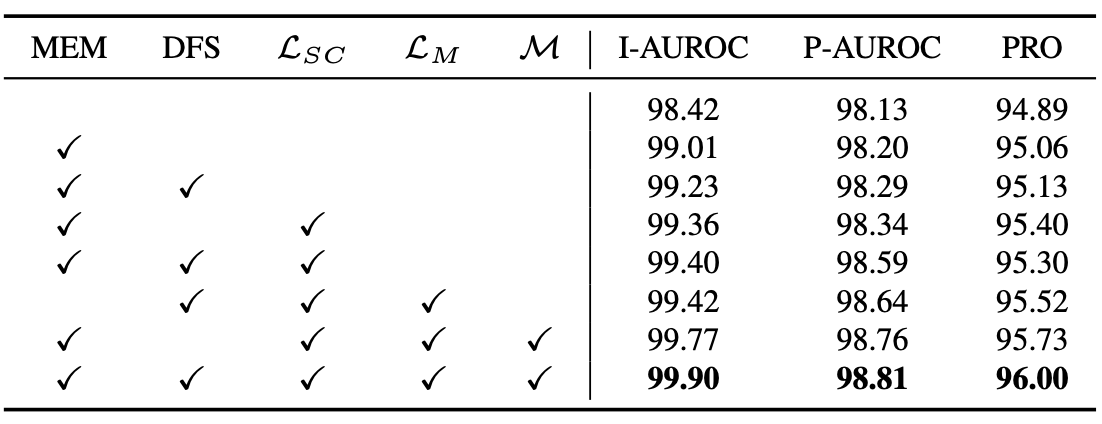 MEM 제거 시: 다양한 스케일의 특징을 포착하지 못해 성능이 하락.
DFS 제거 시: 도메인에 상관없이 모든 특징을 학습하려다 보니, 노이즈가 포함되어 성능이 하락.
LM 제거 시: LSC만으로는 정상/이상 유사도 경계가 뚜렷하게 나뉘지 않아 분류가 애매해지는 현상이 발생.
LSC 제거 시: 근본적으로 대조 학습이 적용되지 않으면서 정상 특징의 응집력이 약해지고, 이상과의 분리도 어려워짐.
MEM 제거 시: 다양한 스케일의 특징을 포착하지 못해 성능이 하락.
DFS 제거 시: 도메인에 상관없이 모든 특징을 학습하려다 보니, 노이즈가 포함되어 성능이 하락.
LM 제거 시: LSC만으로는 정상/이상 유사도 경계가 뚜렷하게 나뉘지 않아 분류가 애매해지는 현상이 발생.
LSC 제거 시: 근본적으로 대조 학습이 적용되지 않으면서 정상 특징의 응집력이 약해지고, 이상과의 분리도 어려워짐.
결론적으로 UniNet은 각각의 모듈이 서로 유기적으로 작동할 때 가장 높은 성능을 발휘하며, 단일 모듈만으로는 완전한 성능을 달성하기 어렵다는 점이 강조됩니다.
직접 실험해보자!
자 그럼 코드를 안돌려볼 수가 없습니다. 저는 진짜 이정도의 성능이 나올까? 우리가 가지고 있는 GPU 환경에서는 속도가 어느정도 나올까?가 궁금했습니다. 제 개인적인 의견으로는 정확도는 당연히 당연히 중요한 부분이지만 그만큼 속도도 실제 산업 현장에서는 무시할 수 없는 요소입니다. 정확도가 1-2% 더 낮지만 속도가 2배 빠르다고 한다면 저는 2배 빠른 모델을 채택하는 것이 낫다고 생각할 만큼 중요한 고려 대상입니다. 그래서 ! 직접 돌려보려고 합니다.
우선 코드는 https://github.com/pangdatangtt/UniNet 이 링크에 오픈소스로 올라가 있습니다.
...
환경 준비
- CPU: AMD Ryzen 9 7950X3D (16코어 32쓰레드, 최대 5.76GHz)
- GPU 모델: NVIDIA GeForce RTX 4090 (2장)
- CUDA 버전: 12.2
- 드라이버 버전: 535.230.02
- OS: Ubuntu 22.04
데이터 셋 준비
- MVTecAD
- 다운로드: https://www.mvtec.com/company/research/datasets/mvtec-ad
- 구조:
|- mvtec |-- bottle |--- ground_truth |--- test |--- train |-- cable |--- ground_truth |--- test |--- train |-- ...
결과
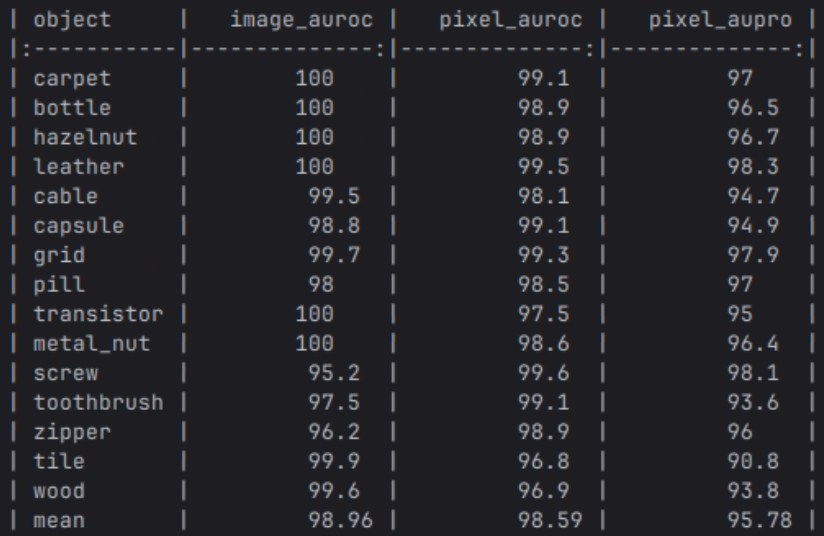
추론 속도는 1장당 약 0.04초가 나왔습니다. 좋은 GPU 쓴거 치고는 그렇게 빠른 속도는 아닌 것 같습니다..
결과는 이전에 제가 사용하던 Anomaly detection 알고리즘의 Pixel 단위의 auroc, aupro보다 좋습니다. 그런데… 이렇게 수치적으로는 결과를 확인할 수 있지만 눈으로 결과 이미지를 확인할 수 없어서 답답했습니다!!!
그래서 조금 더 시간을 들여 score 맵을 원본 이미지에 overlay 하여 시각화하는 코드를 추가했습니다.
결과는.. 두구두구…

대부분 위와 같이 불량을 거의 정확히 찾아내는 모습을 확인했습니다.
 하지만 불량 위치가 아님에도 score 값이 높은 경우도 있었습니다…
하지만 불량 위치가 아님에도 score 값이 높은 경우도 있었습니다…
결론
이처럼 UniNet은 전반적으로 매우 인상적인 성능을 보여주었고, 실제로도 다양한 도메인에서 적용 가능하다는 범용성 측면에서 강점을 지닌 모델이라는 점을 확인할 수 있었습니다.
물론 완벽한 모델은 없기 때문에, 실험 과정에서도 몇 가지 한계점이 눈에 띄었습니다. 예를 들어, 불량이 아닌 영역에서 Score 값이 높게 나오는 경우는 실제 사용 시 오탐(False Positive)으로 이어질 수 있는 요소입니다. 저는 뭔가 파라미터를 조정하면서 실험을 해본 것은 아니기 대문에 조금 더 실험이 필요한 부분이라고 생각합니다.
또한, 추론 속도는 고성능 GPU를 사용했음에도 불구하고 기대보다 아주 빠르지는 않았다는 점도 기억해둘 필요가 있습니다. 실제 산업 현장에서는 연산 속도 또한 중요한 평가 기준이므로, 이러한 부분은 추후에 어떤식으로 개선할지 생각해 볼 필요가 있습니다.
마무리하며
이번 기술 노트를 통해 UniNet이라는 이상탐지 프레임워크가 어떻게 설계되었고, 어떤 기법들이 시너지 효과를 내며 성능 향상에 기여했는지를 함께 살펴보았습니다.
저는 개인적으로 이 논문이 단지 새로운 구조를 제안한 것이 아니라, 기존 연구의 강점을 잘 통합하고 설계적으로 정제되었다는 점에서 훌륭한 아키텍처라고 느꼈습니다.
잘 활용하여 다양한 이상탐지 문제에 폭넓게 활용될 수 있기를 기대합니다.
읽어주셔서 감사합니다!! 도움이 됐기를 바랍니다!

