R&D
개발현황
VectorDB란? – 개념부터 Python 예제까지
-
 관리자
관리자
- 2025.05.12
안녕하세요, 크레플 비전 파트의 하승연 연구원입니다.
이번 Agentic AI Study에서 다뤘던 VectorDB에 대해 개념부터 Python 코드까지 간단히 정리해보려 합니다..
Vector
VectorDB는 Vector + DataBase 입니다.
그럼 여기서 Vector의 뜻이 뭘까요? AI에서 가진 의미는 단어, 문장, 이미지 등 복잡한 데이터를 수치로 표현한 것입니다.
DataBase
그럼 Database는 뭘까요? 개발자라면 많이 들어보셨을 것 같습니다.
딱 Database라는 단어를 들으면 SQL 기반의 DB가 떠오릅니다. 뭐 비슷하지만 vectorDB에서의 DB와 SQL 기반의 DB는 차이점이 있습니다.
아래 표를 보면 차이점을 한눈에 확인할 수 있습니다.
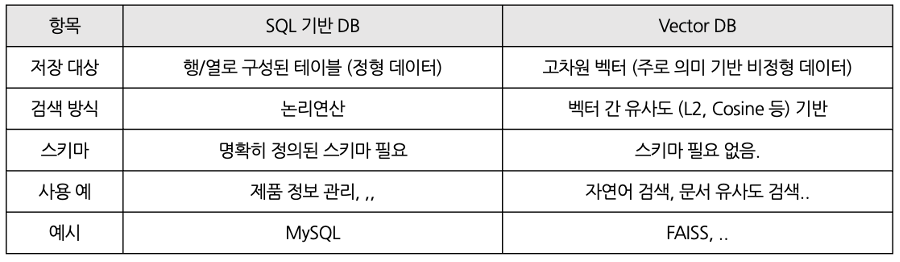
vectorDB에서의 DB는 ‘의미를 담은 벡터’를 저장하고, 유사도 검색이 가능하게 해주는 특수한 형태의 데이터베이스라고 보면 될 것 같습니다. 정리하면 ‘벡터 기반 의미 검색을 위한 데이터 저장소’ 정도가 될 것 같습니다.
VectorDB 개념
그럼 위에서 봤던 Vector와 DB의 개념을 합쳐보면 VectorDB의 개념이 됩니다.
VectorDB란, 임베딩을 통해 생성된 고차원의 벡터 데이터들을 효율적으로 저장하고, 조회할 수 있도록 설계된 데이터 베이스입니다. 쿼리와 정확히 일치하는 행을 찾는 기존의 방식과는 다르게, 벡터 간의 거리나 유사도를 기반으로 쿼리와 가장 유사한 벡터를 찾습니다.
VectorDB 저장 및 쿼리 과정
VectorDB 과정은 아래와 같이 나눌 수 있습니다.
 순차적으로 설명해보도록 하겠습니다.
순차적으로 설명해보도록 하겠습니다.
Embedding
임베딩은 입력을 숫자 벡터화하는 것 입니다. 이숫자는 벡터의 의미를 담고 있습니다. 문장의 의미가 비슷하면 비슷할수록 벡터 값도 비슷하게 나오게 됩니다.
Indexing
인덱싱이란? 수 ~ 많은 벡터들을 효율적으로 검색할 수 있도록 DB에 넣는 과정을 말합니다. 그냥 집어넣는 것이 아니라, 검색이 빠르도록 최적화된 구조로 저장합니다. 수백 ~ 수천개의 데이터라면 그냥 저장해도 되지만, 수십만 ~ 수백만개의 데이터를 그냥 저장하고 검색하게 되면 시간이 엄청나게 오래 걸릴 가능성이 있기 때문에 최적화된 구조로 저장하는 작업이 필요한 것입니다.
Vector Store
벡터들이 저장되어 있는 데이터베이스입니다. 여기에서 유사한 벡터를 검색합니다.
Querying
질문하고 유사 벡터를 찾는 행위입니다. 사용자가 질문을 던지면? 그 질문도 벡터로 변환한 다음 벡터 저장소에 있는 벡터들과 비교해 가장 유사한 벡터를 찾아줍니다. 유사한 벡터를 찾는 방식은 위에 인덱싱을어떤 구조로 어떻게 했냐에 따라 달라지게 됩니다.
Postprocessing
검색된 결과를 필요한 형식으로 정리하는 등의 후처리 과정을 의미합니다.
VectorDB 왜씀?
우선 기존에 키워드 기반으로 검색하는 방식은 “정확히 일치” 해야 찾을 수 있었습니다. 예를 하나 들어보자면? “ AI가 뭐야” 라는 말과 “ 인공지능이란” 이라는 말은 다른 문장으로 인식됐습니다. 그런데 VectorDB는 의미 기반으로 검색하는 것이기 때문에 유사한 문장을 인식할 수 있습니다.
이 고차원 벡터는 대체 어떻게 만들어지는 걸까
‘아니 의미를 담은 벡터가 대체 뭐야 그럼..’ 이렇게 말 할 수도 있는데요, 사실은 의미를 담도록 최대한 훈련된 모델을 사용하여 임베딩 합니다. 대표적인 예로는 BERT, MiniLM, SentenceTransformer 모델들이 있습니다.
그럼 어떻게 검색하는 걸까
우선 사용자의 쿼리도 어떠한 임베딩 모델을 이용하여 벡터로 변환합니다. 그 다음 저장된 벡터들과 비교를 하게 되는데요
이 때 사용하는 기준이 벡터 간 유사도입니다.
예를 들면 L2 거리 (유클라디안 거리), 코사인 유사도, 내적 등.. 을 이용해 가장 가까운 벡터들을 찾아서 그에 해당하는 문장이나 이미지, 문서를 사용자에게 결과로 반환하는 구조입니다.
python 예제코드
아주 간단한 예제 코드를 하나 살펴보도록 하겠습니다. 저는 FAISS 라는 라이브러리와 SentenceTransformer라는 임베딩 모델을 사용하도록 하겠습니다.
우선 예제 코드를 보기 전 FAISS가 뭔지 살펴 볼게요.
FAISS는 Facebook AI Similarity Search 라는 뜻이고 페이스북 AI 연구팀이 만든 대규모 벡터들을 빠르고 효율적으로 검색하기 위한 오픈소스 라이브러리 입니다.
FAISS의 인덱싱 방식에는 여러 종류가 있는데 간단하게 살펴보겠습니다.
- ✨ IndexFlat
벡터들을 그대로 저장
쿼리 벡터 모든 벡터를 하나하나 비교
가장 정확하지만, 속도가 느리고, 메모리 사용량이 많음.
데이터가 작거나 정확도가 정말 중요할 때 사용 - ✨ IndexIVF (Inverted File Index)
전체 벡터 k개의 클러스터로 나눔 (k-means)
쿼리 벡터가 가장 가까운 클러스터로 몇 개만 탐색 → 전체 비교보다는 훨씬 빠름
벡터가 수십만 ~ 수백만 개 이상일 때나 속도가 중요하고 약간의 정확도 손해가 감수 가능일 때 사용 - ✨ HNSW
그래프 탐색 구조로 유사 벡터를 빠르게 찾음.
정확도도 높고 속도도 빠름
M이 각 벡터가 연결할 이웃 노드 수
쿼리가 들어왔을 때 비슷한 것들만 빠르게 타고타고 찾음.
자 이제 예제코드를 살펴봅시다.
아래는 FAISS와 SentenceTransformer를 활용해 간단한 VectorDB 검색을 구현한 코드입니다.
문장들을 임베딩하고, 쿼리 문장과 의미적으로 가장 유사한 문장을 검색해 출력하는 예제입니다.
from sentence_transformers import SentenceTransformer
import faiss
import numpy as np
def load_model() -> SentenceTransformer:
model_name = "sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2"
return SentenceTransformer(model_name)
def build_faiss_index(vectors: np.ndarray, dim: int = 384) -> faiss.IndexFlatL2:
index = faiss.IndexFlatL2(dim)
index.add(vectors)
return index
def encode_texts(model: SentenceTransformer, texts: list[str]) -> np.ndarray:
return model.encode(texts)
def search_similar(index: faiss.IndexFlatL2, query_vector: np.ndarray, k: int = 4) -> tuple[np.ndarray, np.ndarray]:
return index.search(query_vector, k)
def main():
texts = [
"AI가 뭐야?", "기계학습 소개", "인공지능의 뜻", "딥러닝과 머신러닝의 차이",
"커피가 좋아요", "도넛이 맛있어요", "밥을 뭘 먹을까", "닭갈비 먹고싶다", "배고프다",
"강아지와 고양이의 차이", "치와와는 귀엽다", "우리집 강아지는 귀여워", "캣",
"SQL", "파이썬 언어", "프로그래밍"
]
query_text = "음식"
embedding_model = load_model()
vectors = encode_texts(embedding_model, texts)
index = build_faiss_index(np.array(vectors))
query_vector = encode_texts(embedding_model, [query_text])
distance, indices = search_similar(index, np.array(query_vector), k=3)
print("Query:", query_text)
print("Top Results:")
for i in indices[0]:
print("-", texts[i])
if __name__ == "__main__":
main()
이번 예제에서는 비교적 데이터 양이 적기 때문에 IndexFlatL2 인덱스를 사용했습니다.
이는 모든 벡터를 하나하나 비교하는 방식으로, 정확도는 높지만 데이터 양이 많을 경우 속도가 느릴 수 있습니다.
대규모 검색에는 IVF, HNSW와 같은 인덱스를 사용하는 것이 일반적입니다.
실제 실행 결과는 다음과 같습니다.


예제에서는 L2 거리를 기반으로 유사도를 계산했지만,
의미 기반 검색에서는 코사인 유사도나 내적 기반 인덱스를 쓰는 경우도 많습니다.
FAISS에서는 다양한 인덱스를 실험적으로 적용해볼 수 있으니 서비스 목적에 맞게 선택해보세요.
VectorDB 성능의 핵심 요소
- 임베딩 품질: 얼마나 잘 의미를 반영한 벡터를 생성하는지가 핵심입니다.
→ Sentence-BERT, MiniLM 등의 모델 선택이 중요합니다. - 검색 인덱스 구조: 벡터를 어떻게 저장하고 비교하느냐에 따라 검색 속도와 정확도가 달라집니다.
→ FAISS의 IndexFlat, IVF, HNSW 등 구조 선택이 중요합니다.
✨ 마치며
VectorDB는 단순한 데이터 저장소가 아닌, 의미 기반 검색을 가능하게 해주는 강력한 도구입니다.
기존 키워드 기반 검색의 한계를 보완하며, 사용자 질의에 더 적절한 정보를 제공할 수 있다는 점에서
AI 애플리케이션의 핵심 인프라로 자리잡고 있습니다.
이번 기술 노트를 작성하며, VectorDB가 가진 가능성을 사내 서비스에 어떻게 활용할 수 있을지에 대한 고민도 함께 해보게 되었습니다.
예를 들어, 저희의 EQ-0 서비스에서는 과거 발생했던 유사 사례에 대한 검색이나,
작업자 메모·이상 기록을 의미 기반으로 탐색하는 기능 등에 VectorDB를 적용해볼 수 있을 것으로 기대됩니다.
이번 글에서는 VectorDB의 개념부터 주요 처리 과정, 그리고 간단한 Python 실습까지 다뤄보았습니다.
향후 실서비스에서 VectorDB를 활용하거나, 의미 기반 검색 시스템을 구축할 계획이 있다면
임베딩 모델의 선택과 검색 인덱스 구조 설계에 특히 주의를 기울이시길 바랍니다.

